MapReduce is a programming model for processing large dataset. Theory has been introduced more than 10 years ago, and it has been widely known to developer by Hadoop. This is the heart of Hadoop, and now it is being used in many distribute systems.
Though it has been a core of many complex system, the principle is very simple. It is a compound of map and reduce, which is being used in many data structure. In MapReduce, map receives dataset and convert each to key/value form with same logic, and reduce merge outputs to smallser dataset from map.
Example of MapReduce
Most guide documents are showing these with ‘word counting inside vocabulary’ example. I’ll test with “Welcome to blog. This is blog. Welcome to mapreduce.”
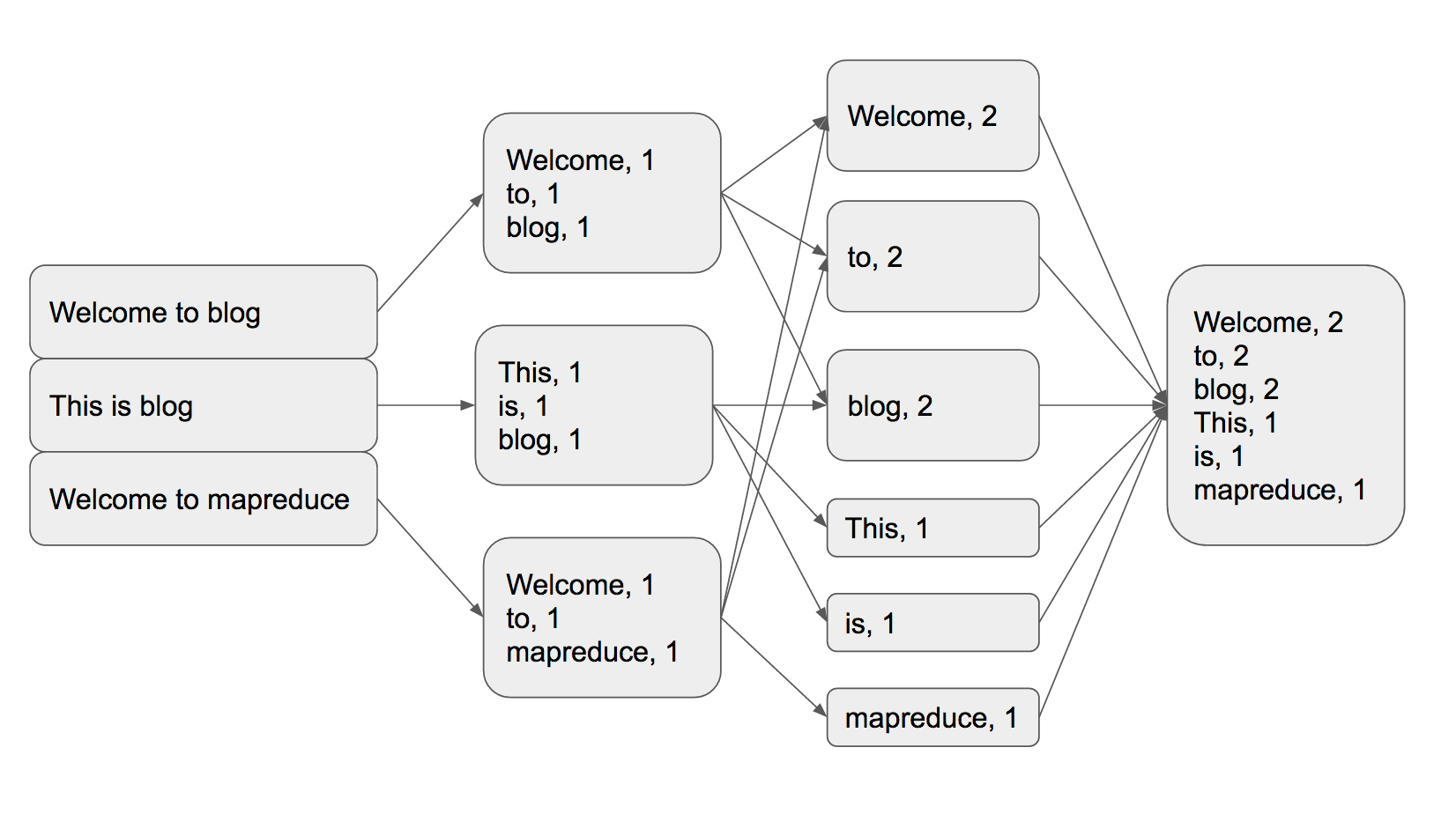
When vocab set comes in, it parses each word and make all as key/value form, which all set has value = 1. And then sort all key/value data with key and add values. Because there are two ‘Welcome’, ’to’, ‘blog’ word inside test vocab, value for these key are added.
{% highlight python %} {% raw %} def mr_map(file_data): mapped = [] words = file_data.split() for word in words: mapped.append({word: 1}) return mapped
def mr_reduce(mapped): reduced = {} for item in mapped: key = item.keys()[0] if key in reduced: reduced[key] += 1 else: reduced[key] = 1 return reduced
file_object = open(‘vocab.txt’, ‘r’) line = file_object.read().strip() print(‘original data:\n’ + line)
map_data = mr_map(line) print(‘mapped data:\n’ + str(map_data))
reduced_data = mr_reduce(map_data) print(‘reduced data:\n’ + str(reduced_data)) {% endraw %} {% endhighlight %}
[vocab.txt]
Welcome to blog
This is blog
Welcome to mapreduce
In this code, ‘mr_map’ functino makes all word in vocab to key/value which key is word and value is 1, so it makes data like this.
[{'Welcome': 1}, {'to': 1}, {'blog': 1}, {'This': 1}, {'is': 1}, {'blog': 1}, {'Welcome': 1}, {'to': 1}, {'mapreduce': 1}]
And reduce process, it sorts each data by key and add the value, which ‘mr_reduce’ does in this code. This is the result.
{'This': 1, 'is': 1, 'Welcome': 2, 'mapreduce': 1, 'blog': 2, 'to': 2}
Actually, there are more simple and well-performed modules in Collection and dict on Python to get this result. This is just for showing how data in MapReduce ins changing on.
Distribute file system
In distribute system, MapReduce divides number of operations on the set of data to each nodes in system. Each node reports back to master system(or node) in certain duration to update current status and check if nodes are working well or not. When any node do not send report, master will define it as dead-server and will send job to other node which works well. Similary, if it needs scale-up, it can be done by adding more nodes and connect with master. That is to say, it makes architecture more stable and becomes manageable.