‘Web scraping’ is a logic to get web page data as HTML format. With this information, not only could get text/image data inside of target page, we could also find out which tag has been used and which link is been included in. When you need lots of data for research in your system, this is one of the common way to get data.
Use parser
But not like CSV or Excel sheet, raw HTML is pretty rough and disordered data.
{% highlight python %} {% raw %} import requests
url = ‘http://bleacherreport.com/' TIMEOUT_SECONDS = 30
response = requests.get(url, timeout=30) {% endraw %} {% endhighlight %}
This is the case of getting raw HTML data from Bleacher Report. It will return data like this.
{% highlight HTML %} {% raw %}
... {% endraw %} {% endhighlight %}It is inconvenient for workers to find target data from here. You need a process of organizing before going further. Maybe you could make a parser yourself, but that’s not an effective way. Python have some great modules for this, and I will use one of this named BeautifulSoap.
Before going on, install it via python package manager with pip install beautifulsoup4.
{% highlight python %} {% raw %} import requests from bs4 import BeautifulSoup
url = ‘http://bleacherreport.com/' TIMEOUT_SECONDS = 30
response = requests.get(url, timeout=30) bs_object = BeautifulSoup(response.text, “html.parser”) {% endraw %} {% endhighlight %}
With this code, raw HTML data has been converted to beautifulsoap object. Now you can get data with text or tag info.
{% highlight python %} {% raw %}
‘find’ method returns the first searched data, while ‘findAll’ method returns all finded data in HTML as list.
this will find data which has ‘p’ tag
p_tag_data = bs_object.find(‘p’) p_tag_data = bs_object.findAll(‘p’)
find exact text ‘NBA’ in HTML
nba_text = bs_object.find(text=‘NBA’) nba_text = bs_object.findAll(text=‘NBA’)
show all data which includes text ‘NBA’
import re nba_text = bs_object.findAll(text=re.compile(‘NBA’))
return all p tag data which includes word ‘fans’
fans_data = bs_object.findAll(‘p’, text=re.compile(‘fans’))
find link tag which includes ‘rel=“canonical”’ element
bs_object.findAll(“link”, {“rel”: “canonical”}) {% endraw %} {% endhighlight %}
Why it needs to use browser
There are a problem on process above, not in parser, but in HTML request process. If we just request data by http request method, it cannot get dynamically rendered part because they are not in HTML file before loading process. Here is some example for this case.
This is the main page of Samsung SDS official site.
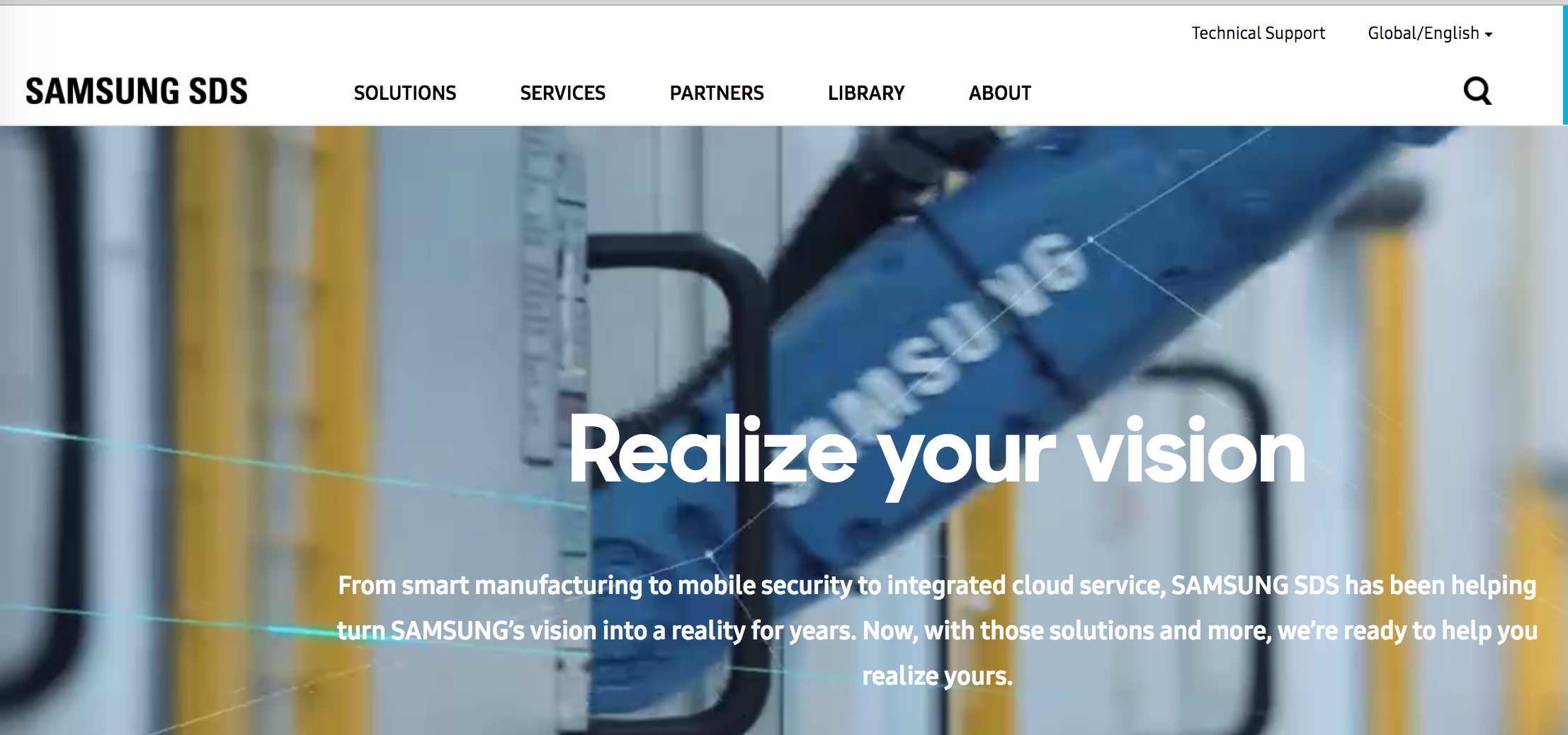
This is the ordinary form of main page. Now let’s check how this will be look like after disabling javascript.

Menu in top has been disappeared, because they are being rendered dynamically from javascript controller. And also, menu texts will not being scraped when you get this HTML page with http request process. So, to get all of these data, you need to get fully rendered result data. For getting it, it has to be rendered in some kind of ‘fake browser’, and that’s why we will use ‘headless browser’.
This is description of headless browser in wikipedia. {% highlight html %} {% raw %} A headless browser is a web browser without a graphical user interface.
Headless browsers provide automated control of a web page in an environment similar to popular web browsers, but are executed via a command-line interface or using network communication. {% endraw %} {% endhighlight %}
Scraping via headless browser
To make scraper via headless browser, we need headless browser, and module to make this run in virtual. I will use PhantomJS here for headless browser, and will make it run with Selenium. You need to install these first.
PhantomJS can be installed by downloading from main page, but can be installed with brew or npm. You can use one of 2 command below.
{% highlight shell %}
{% raw %}
$ brew phantomjs
$ npm -g install phantomjs-prebuilt
{% endraw %}
{% endhighlight %}
Try make a class for scraper.
{% highlight python %} {% raw %} from selenium import webdriver from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
class HBScraper():
def __init__(self):
self.web_driver = webdriver.PhantomJS(desired_capabilities=dict(DesiredCapabilities.PHANTOMJS))
self.web_driver.set_window_size(960, 540)
self.web_driver.set_page_load_timeout(60)
self.web_driver.set_script_timeout(60)
self.web_driver.delete_all_cookies()
def scrape_page(self, page_url):
try:
self.web_driver.get(page_url)
except:
return None
return self.web_driver.page_source
{% endraw %} {% endhighlight %}
HBScraper class is the class for getting ’loaded’ page data. It initiates browser setting like max loading time, window size, etc. on __init__ method. You can do scraping and get scraped result from browser with scrape_page.
Use it like below. {% highlight python %} {% raw %} url = ‘http://bleacherreport.com/'
hb_scraper = HBScraper() bs_object = BeautifulSoup(hb_scraper.scrape_page(url), “html.parser”) {% endraw %} {% endhighlight %}
Because it needs time for loading, scraping with headless browser needs more time to get result than just getting data with HTTP request. But to get exact data of target page, you will need to consider of using it.