asyncio is a high-level API for supporting to implement asyncrounous code, which has been added to python default module from version 3.4. There were some workaround for asyncrounous before, but asyncio is supporting process to run asyncrounous in language level. It will reduce lots of code comparing with old-style way.
Why asyncrounous??
Well, developer knows about what asyncronous is…so what is it good for?
Though I have started python programming since 3.5, I didn’t need to think about this module for about a year. Service I worked had request that can be handle enough with common syncrounous logic, and some of heavy task is processed with distribution queue like celery.
The reason I have been interested is while making some scraper for test. There are 2 code, which does same thing, implemented in old way, and with asyncio and aiohttp, the client/server module based on asyncio.
[sync.py] {% highlight python %} {% raw %} import requests import time
URL_LIST = [ ‘https://www.python.org/’, ‘https://www.javascript.com/’, ‘https://www.amazon.com/’, ‘https://www.netflix.com/’, ‘https://www.scala-lang.org/’ ]
s = time.time() for url in URL_LIST: res = requests.get(url) print(f’requested : {url} / {res.status_code}’)
print(time.time() - s) {% endraw %} {% endhighlight %}
This is simple syncrounous code to fetch data from urls in the list. Most of delays(in my experience, more than 90%…) in scraping process causes on request/response. You really don’t need to worry about speed of parsing, or else. So let’s only focus about requesting, and receiving result.
{% highlight shell %} {% raw %} requested : https://www.python.org/ / 200 requested : https://www.javascript.com/ / 200 requested : https://www.amazon.com/ / 200 requested : https://www.netflix.com/ / 200 requested : https://www.scala-lang.org/ / 200 6.307806968688965 {% endraw %} {% endhighlight %}
It takes about 6.3 sec to fetch urls.
Now, this is the scraper using async/aiohttp. Talking about code later, and go on first. [async.py] {% highlight python %} {% raw %} import asyncio import aiohttp import requests import time
URL_LIST = [ ‘https://www.python.org/’, ‘https://www.javascript.com/’, ‘https://www.amazon.com/’, ‘https://www.netflix.com/’, ‘https://www.scala-lang.org/’ ]
async def fetch(url): async with aiohttp.ClientSession() as session: async with session.get(url) as res: print(url + ’ / ’ + str(res.status))
s = time.time() print(‘start: ’ + str(s))
tasks = [fetch(url) for url in URL_LIST] loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks))
print(’end: ’ + str(time.time() - s)) {% endraw %} {% endhighlight %}
{% highlight shell %} {% raw %} start: 1532329882.60325 https://www.python.org/ / 200 https://www.javascript.com/ / 200 https://www.amazon.com/ / 200 https://www.scala-lang.org/ / 200 https://www.netflix.com/ / 200 end: 2.1449880599975586 {% endraw %} {% endhighlight %}
This logic took 2.1 sec for response. What makes the difference?
Sync / Async
sync.py is the most generic way to handle list data we used to saw in lots of codes. It reads the data from the list, and do something withit one by one. The problem is, action of requesting server causes delay by waiting response of request. So in platform which should not allow freezing, like Android, it forces to implement http request actions in sub-thread to avoid lack on main(UI) thread.
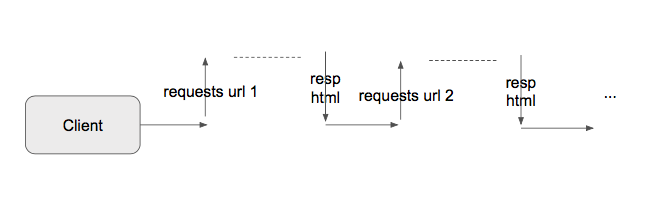
As you can see, main client thread is doing nothing while waiting for response, and this makes the delay of process. Surely, there are ways to use thread in python. But because issues on memory management, python setup GIL(global interpreter lock) to keep it thread-safe, so multi-threading usually cannot improve performance for this.
So, how can asyncio make this better?
Event loop and coroutine
This is sample code in python document: {% highlight python %} {% raw %} import asyncio
async def compute(x, y): print(“Compute %s + %s …” % (x, y)) await asyncio.sleep(1.0) return x + y
async def print_sum(x, y): result = await compute(x, y) print("%s + %s = %s" % (x, y, result))
loop = asyncio.get_event_loop() loop.run_until_complete(print_sum(1, 2)) loop.close() {% endraw %} {% endhighlight %}
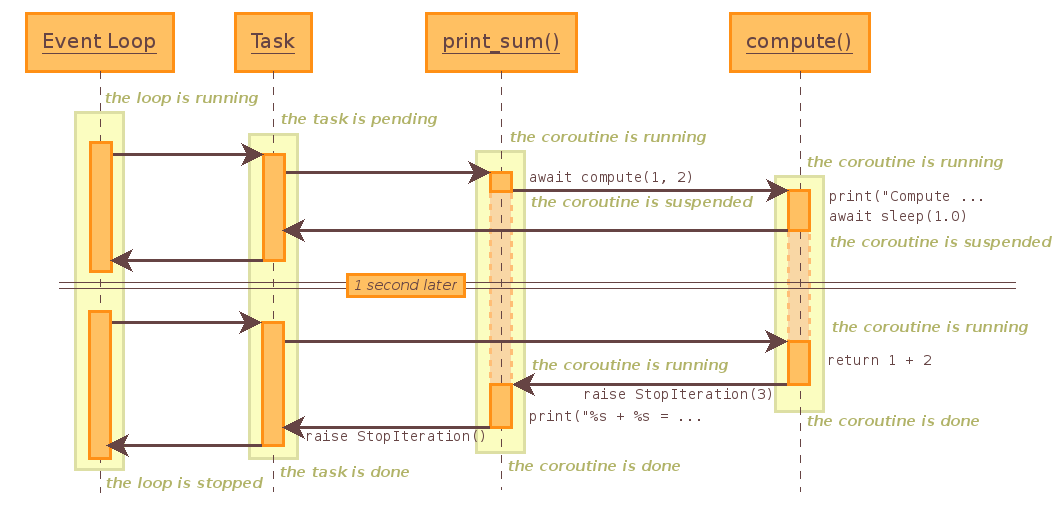
By calling asyncio.get_event_loop(), you can get event loop, the repeated process of registering for events and reacting to them as they arrive. Think like kind of message queue. In this loop, we can put in coroutine which needs to be done. If you see the module compute, and print_sum, you can find async def in front of it. This is for to make these as coroutine.
Now loop.run_until_complete(print_sum(1, 2)), it will put in print_sum(1, 2) to the loop and wait until it finish.
If you see inside print_sum, there are await compute. This await keyword is being used in front of coroutine or task, and it means to wait for the result from it. And in compute, there are one more thing await asyncio.sleep(1.0), and as you can expect, it will wait for 1 second before returning value x + y.
So the process will be:
- Put coroutine to event loop
- Run event loop
- Start
print_sum(1, 2) - Call
compute(1, 2) - Wait 1 second
- Return 3(1 + 2)
- Print “1 + 2 = 3”
- Close loop
You can see this in flow chart:
Asyncio and aiohttp
Back to the code again: [async.py] {% highlight python %} {% raw %} import asyncio import aiohttp import requests import time
URL_LIST = [ ‘https://www.python.org/’, ‘https://www.javascript.com/’, ‘https://www.amazon.com/’, ‘https://www.netflix.com/’, ‘https://www.scala-lang.org/’ ]
async def fetch(url): async with aiohttp.ClientSession() as session: async with session.get(url) as res: print(url + ’ / ’ + str(res.status))
s = time.time() print(‘start: ’ + str(s))
tasks = [fetch(url) for url in URL_LIST] loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks))
print(’end: ’ + str(time.time() - s))
loop.close()
{% endraw %}
{% endhighlight %}
It will be more easier to understand now.
aiohttp.ClientSession().session is a method to request data with url. It has the same role with request.get in sync sample. But to use blocking I/O method(which stops the process until ends) such as request.get, you need to execute parallel by using run_in_executor. To avoid this, aiohttp offers lot of module to make this more simple.
This is the process:
taskswill keep list of coroutines which are fetching each url inURL_LIST.- Get event loop
- Put in coroutines to fetch url, and run the loop.
- Fetch the data from url asynchronous.
- Close the loop after all url data has been fetched.
Really multi-thread?
As mentioned about GIL above, this process is not actually using lots of thread, by python specification. It means it is not always useful. Moreover, it has more complexity of implementation comparing with coding in previous ways. But at least in scraping case, and other cases that blocking I/O could effect performance, it can use blocking time(request/response) to not wait and do other things such as request other data, or processing it.