In big data era, by increasement of data size, lots of companies who treated this needed to concern about speed. But HDFS, which usually being used to store big data, couldn’t show enough performance, by blocking from I/O. Data engineers started to research on this, and lots of projects has been introduced, still now. Apache Spark is one of them, and now become most popular between competitors.
It has not been a long time since I’ve looking on data engineering, so though I’ve heard of the name and try simple shell command, it is the first time to go on bit deeper.
Apache Spark
Apache Spark has been started about 6 years ago. When project first disclosed, it focused on processing data in parallel across a cluster, but the biggest difference was, it works in-memory to increase performance.
Yes, in that time, it was the most impactive point. But now, that’s not all.
By document, it saids: {% highlight shell %} {% raw %} Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming. {% endraw %} {% endhighlight %}
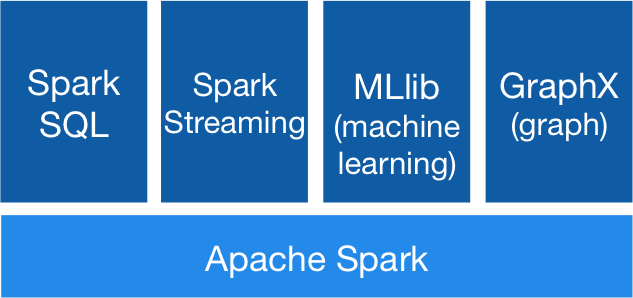
Currently, the most strength of Spark, is that it includes everything for data engineering. Not only streaming, it supports SQL query by Spark SQL for data process, machine learning with MLlib, and more. Now they don’t need to study about connecting these feature in their system. Also, it supports API with various languages.
Simple start-on with word count example
You can install spark by downloading binary, or if you are MacOS user, just can use brew. When downloading binary, you need to select Hadoop version you are using.
Setup path in .bash_profile(for MacOS) after download
{% highlight shell %}
{% raw %}
…
export SPARK_HOME=/path/to/spark/
export PATH=$PATH:$SPARK_HOME/bin
…
{% endraw %}
{% endhighlight %}
If you succeed, you can run spark shell command with spark-shell:
{% highlight shell %} {% raw %} $ spark-shell 2018-08-11 13:34:55 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform… using builtin-java classes where applicable Setting default log level to “WARN”. To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://192.168.3.3:4040 Spark context available as ‘sc’ (master = local[*], app id = local-1533962107204). Spark session available as ‘spark’. Welcome to ____ __ / / ___ / / \ / _ / _ `/ __/ ‘/ // .__/_,// //_\ version 2.3.0 //
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_102) Type in expressions to have them evaluated. Type :help for more information.
scala> {% endraw %} {% endhighlight %}
This shows that install has been done. Now let’s check this works well.
This is the word count example, the most basic tutorial for Spark, and all other data processing tools.
If you are trying to run code in spark-shell, it will load sc automatically to make use directly without defining. This is SparkContext, kind of like driver to work with functions in spark cluster.
Prepare dummy text data into hdfs, to use it in spark shell. Default directory is /user/<username>.
{% highlight shell %}
{% raw %}
scala> val lines = sc.textFile(“spark-guide.txt”)
lines: org.apache.spark.rdd.RDD[String] = spark-guide.txt MapPartitionsRDD[1] at textFile at
scala> val words = lines.flatMap(_.split(" “))
words: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at
We can figure out lines is some kind of instance which includes text file, and words contains the set of words inside text. Before going on further, we need to know in detail, what happened here.
RDD, DAG
Resilient Distributed Dataset, a.k.a. RDD, is a fault-tolerant collection of elements that can be operated on in parallel, used inside Spark cluster. It can be generated by parallelizing an existing collection in Spark, or referencing dataset from external storage such as HDFS, or else.
In example above, lines are text file RDD using SparkContext’s textFile method. This method takes an URI for the file (either a local path on the machine, or a hdfs://, s3a://, etc URI) and reads it as a collection of lines.
The textFile method also takes an optional second argument, which defines the number of partitions of the file. By default, Spark creates one partition for each block of the file (blocks being 128MB by default in HDFS).
RDDs support two types of operations: transformations, which create a new dataset from an existing one, and actions, which return a value to the driver program after running a computation on the dataset. As you can understand now, words are a transformed new RDD which has set of words from text.
But in current status, it has not been ‘actually’ done.
All transformations in Spark are lazy. It means actual work is not being done though code has been processed. In cluster, it is just remembering the flow of RDDs, and the graph of flow is called as DAG(Directed Acyclic Graph).
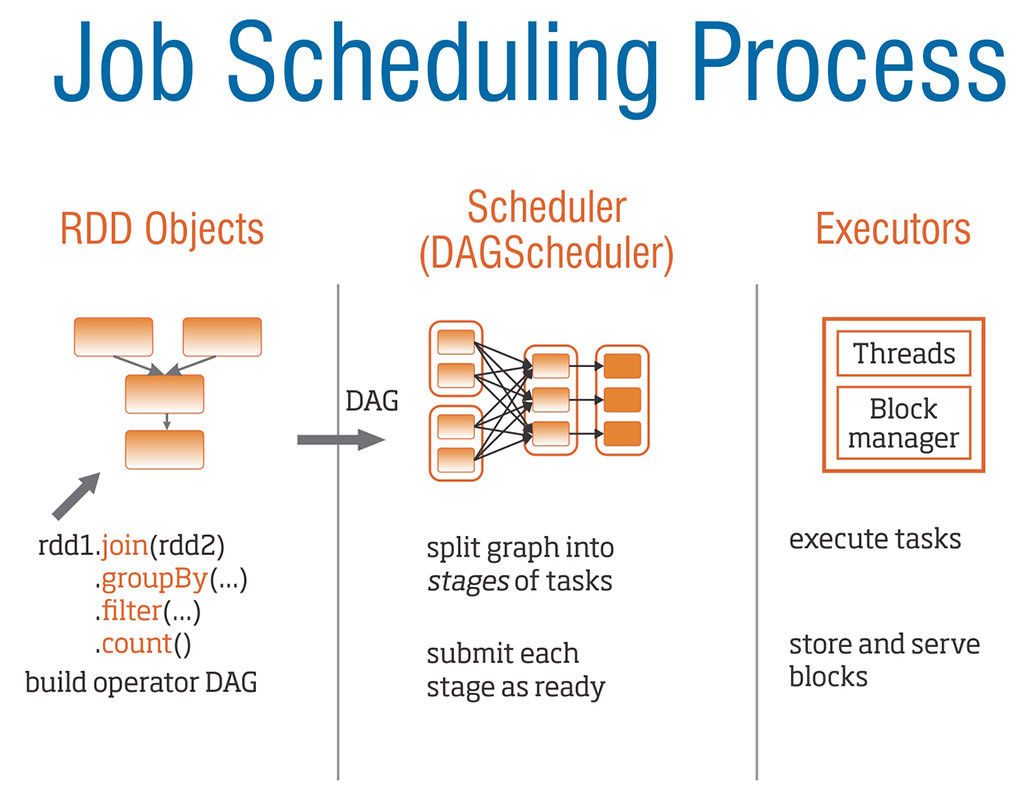
The transformations are only computed when an action requires a result to be returned to the driver program. This design enables Spark to run more efficiently.
Process in word count
Now let’s go back to the word count again.
{% highlight shell %}
{% raw %}
scala> val pairs = words.map(word => (word, 1))
pairs: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at
scala> val wordCounts = pairs.reduceByKey(+)
wordCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at
These lines also creates RDDs and put it on to DAG. pairs are mapping the set of words, to make each of them as ‘(word, 1)’, and wordCounts reduce these pairs by word, and add on number. It is exactly same process with MapReduce.
{% highlight scala %} {% raw %} scala> wordCounts.foreach(r => println(r)) (“added”,1) (Spark,6) (languages.,1) (it,2) (shared,3) … (supported,1) (shell,2) (variable,2) (Users,1) (program,,1) (supports,1) (function,3) (one.,1) (program,1)
scala> {% endraw %} {% endhighlight %} Now, the print action is required, so DAG will be executed to show the mapped data.
For now, this is just a beginning of Apache Spark. I’ll try to keep on working other samples, ‘how-to-use’s, and configuration of system.