I’ve received a request for a simple demo few weeks ago, which needs to catch-up real time data, and show the result on simple webpage. I’ve thought it would be simple at first meeting. But because I was first on using micro-service and traffic size was way more bigger than I thought, I faced with lot of issue on work.
This is the summary of the development.
Request
This is the basic flow to do.
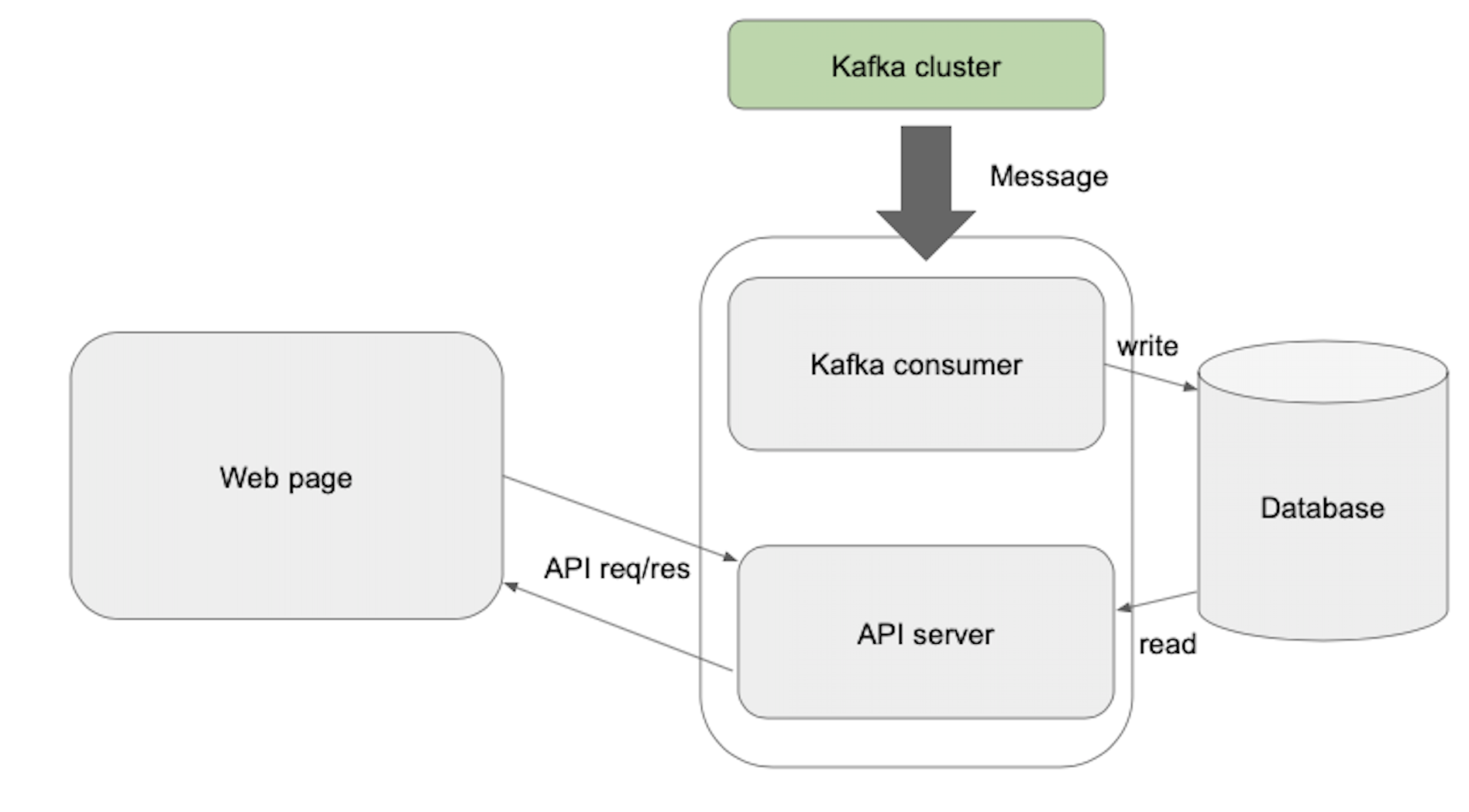
- Consume message from specific Kafka topic
- Parse message to defined format, and save on DB
- Web page repeatedly requests data to API server
- API server responds the data in DB to web page
Health-check, and Actuator
This app will be setup as part of big micro-services . As you know, micro service is a cluster consist of many services separated by domain(or else). And because services are running separately, cluster needs to monitor each service instances are running well without exception.
For this each service usually make an endpoint(usually /health) which will return the status of the service. Returning value does not need to be complicated, just let cluster know that I’m okay. To make it more simple, Spring has a module for this named Actuator.
You don’t need to do something on your code. Just add a line on gradle build file: [build.gradle.kts]
...
dependencies {
implementation("org.springframework.boot:spring-boot-starter-actuator")
...
}
Run the server, and call /actuator
$ curl localhost:8080/actuator -i
HTTP/1.1 200
Content-Type: application/vnd.spring-boot.actuator.v3+json
...
{"_links":{"self":{"href":"http://localhost:8080/actuator","templated":false},"health":{"href":"http://localhost:8080/actuator/health","templated":false},"health-path":{"href":"http://localhost:8080/actuator/health/{*path}","templated":true},"info":{"href":"http://localhost:8080/actuator/info","templated":false}}}
This automatically creates the endpoint which offers service status. If you access to /actuator/health, it will show:
$ curl localhost:8080/actuator/health -i
HTTP/1.1 200
Content-Type: application/vnd.spring-boot.actuator.v3+json
...
{"status":"UP"}
Of course you can customize the response informations. See official actuator document for more.
Kafka consumer setup
Different with tutorial, it needs to handle 10~100Mb/sec payloads from producer server. To handle it more efficiently, some of settings need to be changed.
fetch.max.bytes / max.fetch.partition.bytes
It is to define the maximum amount of data that it wants to receive from the broker when fetching records. fetch.max.bytes means the maximum size which consumer can receive, and max.fetch.partition.bytes is the maximum fetch size from each partition.
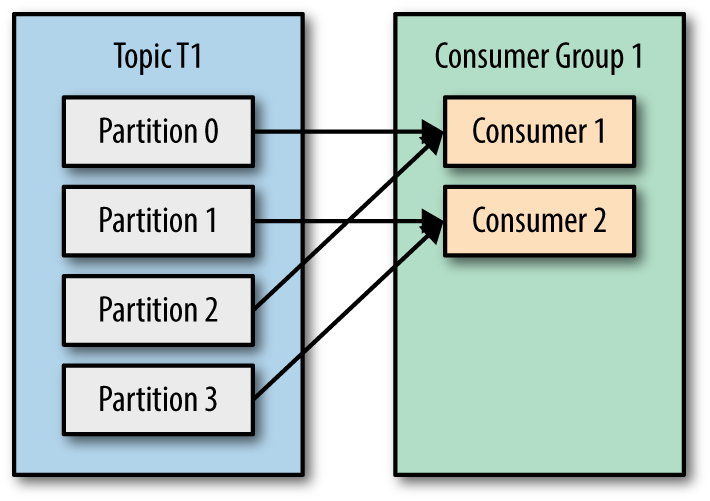
Default value are both 1048576, but because avg. size of fetched data was way more bigger than this so needed to update it. Because the topic I’ve consuming was with 10 parition, I’ve setup fetch.max.bytes as 100Mb, and max.fetch.partition.bytes to 10Mb.
fetch.min.bytes
Opposite with above, it define the minimum data size that it wants to receive from the broker on fetching. Keeping default value(1bytes) will makes consumer response to producer too oftenly, so update to 1Mb.
fetch.max.wait.ms
The maximum time the server will block before answering the fetch request if there isn’t sufficient data to immediately satisfy the requirement given by fetch.min.bytes. It means that consumer will wait during setup time passes until message to fetch becomes bigger than fetch.min.bytes. Default is 500ms, but this setting could cause delay while message piles up in a flash, so reduced to 100ms.
receive.buffer.bytes
The size of the TCP receive buffer to use when reading data. Default is 65535, but seems needed to update with bigger value for receiving massive data.
Because I’m not Kafka engineer, I was undergoing trial and error, and still not sure this is the best answer. But thankfully, it worked well than before(with default setting).
Checking null inside object parsed by Gson
Think of making logic to check ‘key’ in json object, and return false if value is invalid. If you are using Gson for parsing json format data, this logic for null-check could not work.
|
|
Parsing logic in Gson, seems making null value into JsonNull object defined by Gson, instead of keeping it as own format. So you need to replace last code to:
...
if (jse.asJsonObject.get("key").isJsonNull()) {
return false
}
...
Currently, javadoc in code is commented as returning null:
|
|
but it was not working in my case. So, if you want to make it more safe, do it as:
|
|
double-checking.
DB Indexing
While developing, there were request to show additional data. To get this data, additory DB table was needed. So I’ve created new one, with dumped data(around 500,000 row).
Message format was something like(different with real one…):
|
|
and new table row was like:
| id | name | |
|---|---|---|
| 1 | user-1 | email-1 |
| 2 | user-2 | email-2 |
| 3 | user-3 | email-3 |
| … | … | … |
and need to find name and get email of every message data.
So process was:
- Receive message from Kafka
- Get name from message
- Find email from new table by name
- Merge data and save to record
After process has been updated, performance has been much slower, and caused big lag on consumer. I’ve tried to fix by tuning Kafka consumer configuration on first time, but problem has been fixed very simple, by indexing name column.
Indexing is a way to optimize the performance of a database by minimizing the number of disk accesses required when a query is processed. This requires additional space for index column, but it was not a big matter comparing with this issue. So I’ve create new flyway migrate file for update:
[v0_2__add_index_name.sql]
ALTER TABLE user_info ADD INDEX `idx_name` (`name`);
Consumer lag has banished, and more, CPU usage of DB has decreased.