Making from scratch is a typical way to learn something. Because most of modern programming languages has its own package manager, it is simple to get implemented module with single command. But it does not mean I totally understand how that works, so I’ve plan to start review & mocking project by topic.
The motivation was GitHub project, build-your-own-x. You can find lots of posts about building something from scratch here.
I’ll go deep with key-value store on this post.
Key-Value store
As you can expect on the name, key-value store(or storage, or database) is a data storing module which keeps data as key-value format. Most simply you can think of Object in javascript, or dict in python. These are keeping value as key-value set, and let user can access value by key(or opposite). Most of them are optimized of getting value from key by hash-table, or some other logics.
It is type of non-relational data, so have different working logic with RDB. It treat the data as a single opaque collection, which means it can have different fields for every record. It makes storage easy to scale, and give more flexibility.
Concept of log-structured file system
Though computing performance has been improved massively(and still going on), data access performance is still big issue for software engineering field. Log-structured file system(aka LFS) is one theory for this approach.
Fundamental of Log-structured file system(aka LFS) has been introduced in early 90’s. In that time, people investigated sequential IO will be getting faster than random IO by increasement of physical RAM. So first approach is to
- Keep written data on in-memory segment, and write to log when it is full
- Segment write is handled in sequential manner
Let’s see how this buffer written in disk. This is the data structure which is being used on LFS:
- Inodes: Physical block pointers to files.
- Inode Map: This table indicates the location of each inode on the disk. The inode map is written in the segment itself.
- Segment Summary: This maintains information about each block in the segment.
- Segment Usage Table: This tells us the amount of data on a block.
Consider the following figure, showing a data block D written onto the disk at location A0. Along with the data block is the inode, which points to the data block D. Usually, data blocks are 4 KBs while inodes are about 128 bytes in size.

‘D’ is the data block and it is being stored at A0. After data block, there are following inode which has the location of the ‘D’. It makes data stored sequentially and make data accessible via inode.
I’ll not go deeper about LFS for now, because it is out of scope of what I’m trying to do. For more, you could refer here, or this.
Basic implementation
My implementation is following the part of guide in pingcap/talent-plan. It includes the fundamental of key-value store(following the design of bitcask project), and other great training programs. Prefer to try on if you’re available…
I’ve started with including most basic function on key-value store, put, get, and open. In bitcask document, it saids:
- Writes are append-only, not overwriting existing file. It forces writing to be sequential, and do not need to ‘seek’ for writing.
- The key to value index exists in memory.
To follow this rule, it keeps Map object in memory, and stores key with position information.
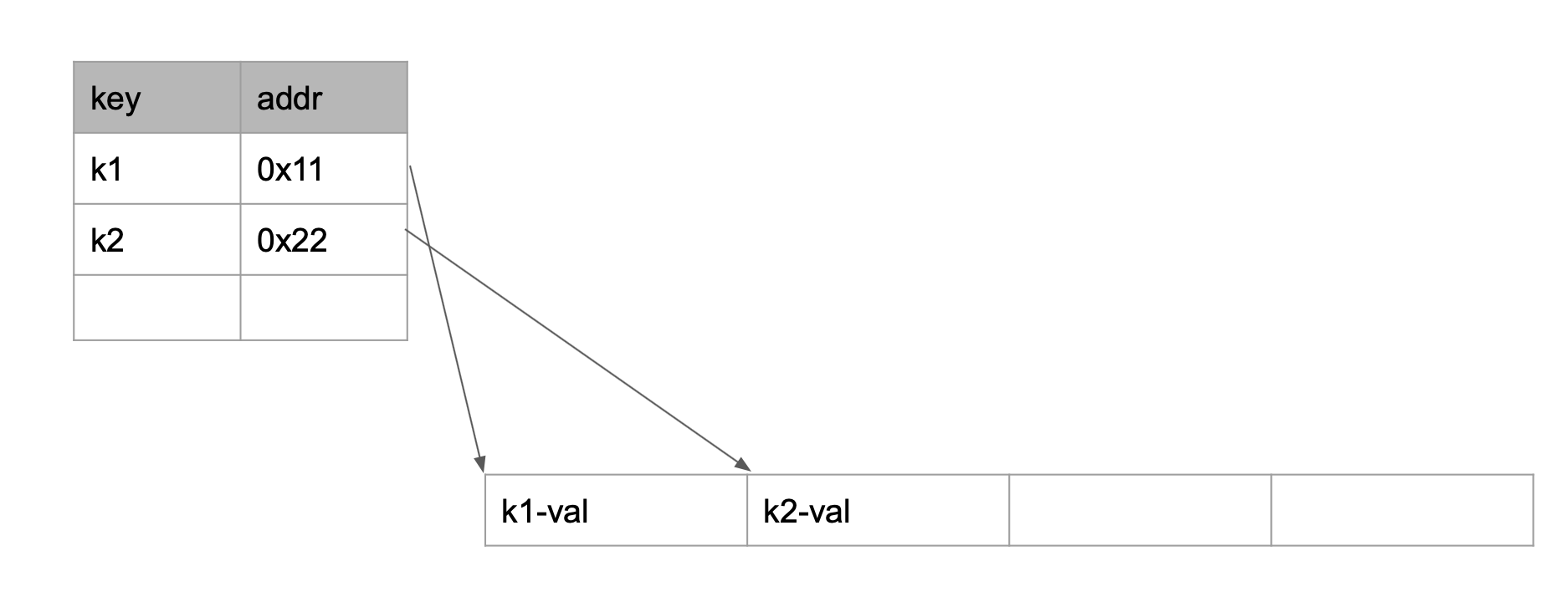
For get function, it will access via position information in this ‘Map’ object where key-value exists.
When open event happens, it will create new log file instead of overwriting existing one, and put current log info to in-memory for writing purpose. In put, it will keep end position of buffer and let next put event to refer this, to keep key-value in sequential order.
Real bitcask rule is way more complicate for disk space optimization, concurrency, and more. But for now, I’ll only think about this feature. Probably I could keep work on in the future.
Open
Make to object readers and index_map. It is to get data buffer for log, and position information of key-value pairs. Then make logs_list to get list of data files in log directory.
|
|
For every logs, setup index(position) information for each map in log.
|
|
After index has been generated, index map will be like:
"key-0": CommandPos { gen: 3, pos: 0, len: 41 }, "key-1": CommandPos { gen: 3, pos: 41, len: 41 }, "key-2": CommandPos { gen: 3, pos: 82, len: 41 }, "key-3": CommandPos { gen: 3, pos: 123, len: 41 },
...
|
|
Now create new log file, and keep writer object to in-memory buffer for write-only.
Append data
On put event, get ‘position’ information from writer object, and setup new key-value pair on the end. After then, update index store.
|
|
Read from key
|
|
For get, if key exists in index_map, it will find position information and get data from position in reader object.
For now…
I’ve update this work in my repository. I’ve named as bawikv, motivated from rocksdb(‘bawi’ means ‘rock’ in Korean). Current work is just a copycat of pingcap/talent-plan project, but I’m planning to add more features to make this affordable for external user.
There will be a chance to treat about this.