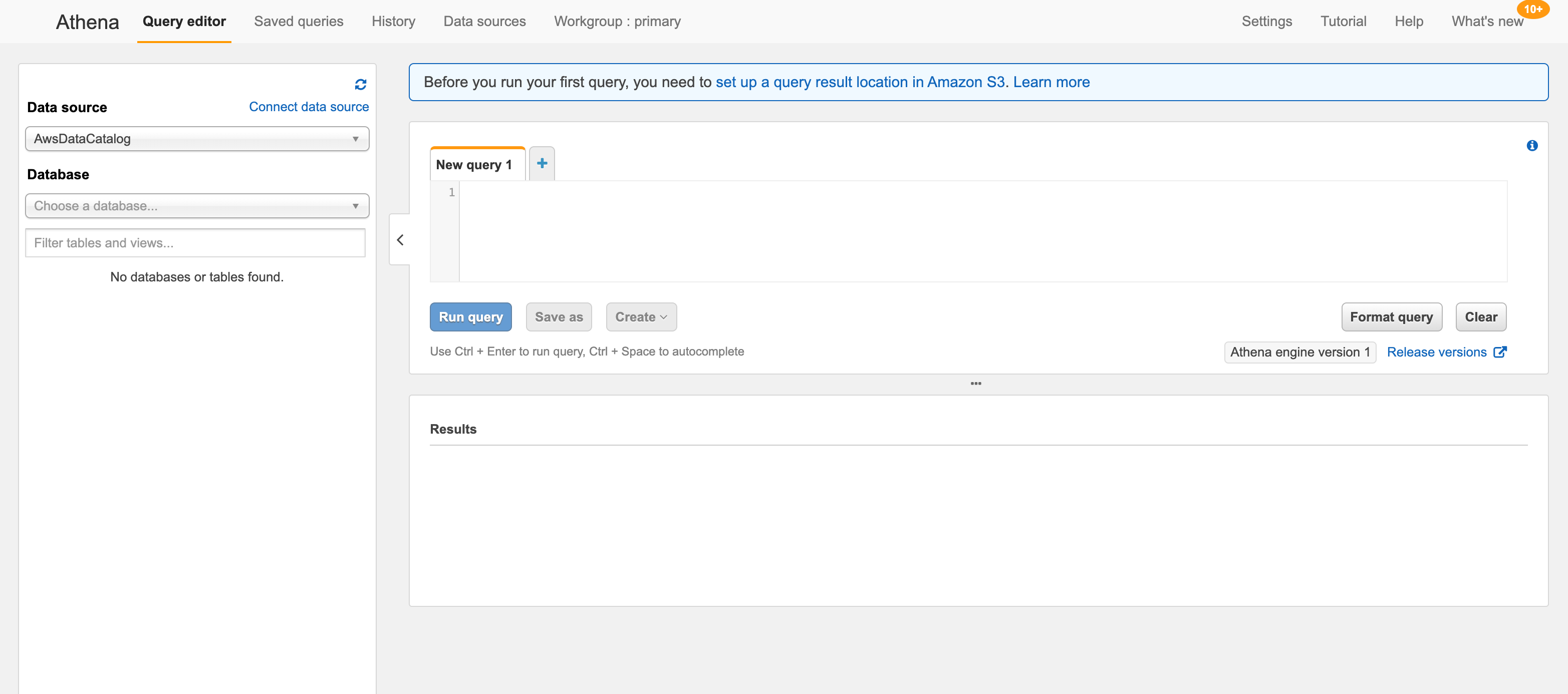
Amazon Athena is a service to analyze data stored in S3 with interactive SQL query. You don’t need additional setup, and only need to pay for the queries you’ve run.
It is usually being used by data scientists, or business developer who needs to get insights from big data(probably stored inside S3, or else).
Also for data engineers, it can be needed to get specific data to construct data process logic. And in this case, they may need to create application to automate querying job. Of course, Amazon is offering SDK for the developers.
This is a note of process to receive/treat data executed by Athena query, inside data pipeline.
Using official SDK(2.x)
Let’s see SDK for Athena first. Newest version for AWS is 2.x.
Now query can be submitted with client, but there are several configuration to be done:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
importsoftware.amazon.awssdk.services.athena.model.{QueryExecutionContext,ResultConfiguration,StartQueryExecutionRequest}// ...
valQUERY_STRING="SELECT * FROM user ORDER BY created_at DESC LIMIT 10"valOUTPUT_PATH="s3://output/athena"valqueryExecutionContext=QueryExecutionContext.builder.database("athena_project").buildvalresultConfiguration=ResultConfiguration.builder.outputLocation(OUTPUT_PATH).buildvalstartQueryExecutionRequest=StartQueryExecutionRequest.builder.queryString(QUERY_STRING).queryExecutionContext(queryExecutionContext).resultConfiguration(resultConfiguration).build
This is to submit ’newest 10 row inside user dataset of database athena_project.
Athena SDK requires user to define ‘output location’ to store result data in S3. This can be useless if you just want to check the result, but it is a requirements, and it will return error when not defined with ResultConfiguration.builder.outputLocation.
Query execution can take time depend on database size or complication of query, so need to add wait loop logic.
// get id from 'startQueryExecutionRequest' above
valqueryExecutionId=startQueryExecutionResponse.queryExecutionId()valgetQueryExecutionRequest=GetQueryExecutionRequest.builder.queryExecutionId(queryExecutionId).buildvargetQueryExecutionResponse=nullvarisQueryStillRunning=truewhile(isQueryStillRunning){getQueryExecutionResponse=athenaClient.getQueryExecution(getQueryExecutionRequest)valqueryState=getQueryExecutionResponse.queryExecution.status.statequeryStatematch{caseQueryExecutionState.FAILED=>thrownewRuntimeException("The Amazon Athena query failed to run with error message: "+getQueryExecutionResponse.queryExecution.status.stateChangeReason)caseQueryExecutionState.CANCELLED=>thrownewRuntimeException("The Amazon Athena query was cancelled.")caseQueryExecutionState.SUCCEEDED=>isQueryStillRunning=falsecase_=>Thread.sleep(1000)}logger.info("The current status is: "+queryState)}
It will execute query execution state every 1 second until state is success or failed(cancel), and move on to next step if query execution has done successfully.
If process is going well until here, you can find the result by GetQueryResultsRequest, using query execution ID.
But if this process is inside data pipeline with big data processing engine(such as Spark), you might need to load the result inside spark dataframe. In this case, you can read the result using output CSV file(which defined above).
But this writing to file + read into dataframe seems causing unnecessary process, because actually it don’t need to write file if it can be read directly to dataframe.
In this case, you can use JDBC driver for this approach.
One bad thing is, driver has not been updated in maven repository for around 3 years, so several features will not work. You should download the driver library, and put into /lib directory inside project.
(For example Catalog option will not work with old version)