Deploying DAG to Managed Airflow(AWS), with GitHub Action
1157 6 mins
Usually, data pipeline requires complex workflow. Generated data should be sent to various endpoints, and needs to be manufactured by status while moving on.
For example, if there’s a log file stored in S3, the pipeline may need to
Send this to ELK, for monitoring purpose every 10 minute
Format to filter useless columns, and send to BigQuery for researching insights, every hour.
Or more…
It is pretty complex to design workflow of jobs which need to handle each processes. So lot of great engineers had created project to make this done in simple way.
Airflow
Airflow is a platform to create/schedule/monitor workflows. This workflow are consist of 1 or more task, which is an implementation of an Operator. There are PythonOperator to execute Python code, BashOperator to run bash commands, and much more to run spark, flink, or else.
This is simple way to create workflow, consist with bash task and python task.
Order of these task can be design easily by using >>
fromairflowimportDAGfromairflow.operators.bash_operatorimportBashOperatorfromairflow.operators.pythonimportPythonOperatordefprint_context(ds,**kwargs):"""Print the Airflow context and ds variable from the context."""pprint(kwargs)print(ds)return'Whatever you return gets printed in the logs'# Initiate DAGdag=DAG('tutorial',default_args=default_args,schedule_interval=timedelta(days=1))# define bash task with BashOperatorbash_task=BashOperator(task_id='run_after_loop',bash_command='echo 1',dag=dag)# define python task with PythonOperatorpy_task=PythonOperator(task_id='print_the_context',python_callable=print_context,dag=dag)# define order of workflow. Run bash task first, and python task after it ends.bash_task>>py_task
DAG object is to nest the tasks. This defines the detail configuration of the workflow, including schedule to run, or else.
If you’re working with Scala/Java and need to run spark jobs, you can use airflow-livy-operators module to call it simple.
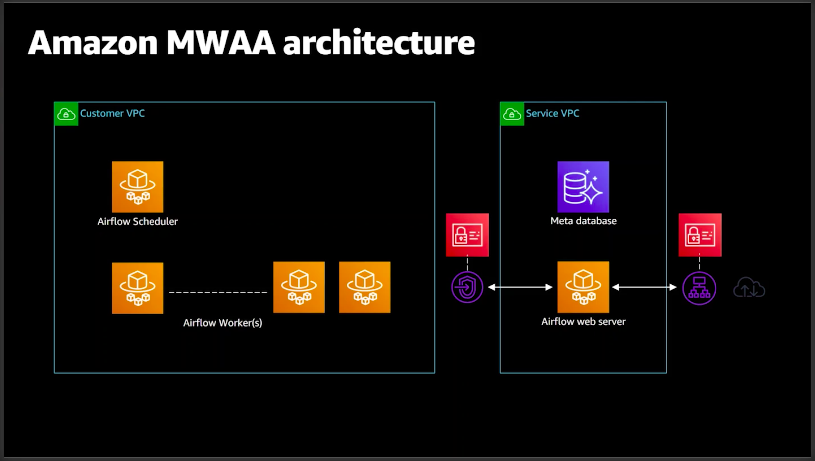
If you’re AWS user, you can think of using MWAA -Managed Workflows for Apache Airflow, which is managed orchestration service for Apache Airflow inside AWS. It makes easier for AWS user to set up and operate end-to-end data pipelines in the cloud at scale.
Deployment with GitHub Action
Copying python workflow scripts to cloud storage manually is pretty inconvenient. Moreover for security reason, uploading/downloading files through console is not a safe way to work, and that is one of the reason to use CI tool for uploading.
By using GitHub Action, above the pros of CI tool, you can easily control triggering by manually,or by github events(pull request, push…) with defined parameter.
Now let’s describe the script to trigger the DAG.
By defining workflow_dispatch, you can make workflow which will run only by user’s action through Actions Tab in project page.
I’ve setup parameter dag_name, to get DAG name which needs to be triggered inside mwaa. Now you can use this parameter as github.event.inputs.dag_name inside job.
And run the following command to call API https://$WEB_SERVER_HOSTNAME/aws_mwaa/cli with token and hostname. It will be done correctly if AWS environment has been setup well.
1
2
3
4
5
6
7
8
9
10
# Get token and hostname, for mwaa triggeringCLI_JSON=$(aws mwaa create-cli-token --name {YOUR_HOST_NAME})\
&&CLI_TOKEN=$(echo$CLI_JSON| jq -r '.CliToken')\
&&WEB_SERVER_HOSTNAME=$(echo$CLI_JSON| jq -r '.WebServerHostname')# Trigger DAG by APICLI_RESULTS=$(curl --request POST "https://$WEB_SERVER_HOSTNAME/aws_mwaa/cli"\
--header "Authorization: Bearer $CLI_TOKEN"\
--header "Content-Type: text/plain"\
--data-raw "trigger_dag ${{ github.event.inputs.dag_name }}")
The value of CLI_RESULTS looks like:
1
2
3
4
{"stderr":"<STDERR of the CLI execution (if any), base64 encoded>","stdout":"<STDOUT of the CLI execution, base64 encoded>"}
so parse the value like following. If the result is OK, there will be no value inside CLI_STDERR.
There can be cases that if you want this work only be done in main branch, to avoid unofficial version to be triggered. You can make action to check the current branch, and decide whether to be triggered or not:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
jobs:trigger:steps:- uses:actions/checkout@v2- name:Trigger workflowenv:# setup AWS environments valuerun:| # If branch is not `main`, exit the process
if [[ "$GITHUB_REF" != "refs/heads/main" ]]
then
echo "Trigger only allowed in `main` branch"
exit 1;
fi
Or, maybe you could want this triggering job only be allowed to specific users. In this case, you can filter user by GitHub ID. Make file team_member.txt and write down the user’s ID who can run the job, and:
jobs:trigger:steps:- uses:actions/checkout@v2- name:Trigger workflowenv:# setup AWS environments valuerun:| # If user is not in the list, exit the process
while read line; do
if [ ${{ github.actor }} == "$line" ]; then
echo "${{ github.actor }} is authorized user"
ALLOWED_USER=${{ github.actor }}
break
fi
done < "team_member.txt"
if [ -z "$ALLOWED_USER" ]; then
echo "Job triggered by unauthorized user"
exit 1
fi
There are many more variations to manage complex workflows, or you can make script for customized workflow yourself.